
Storage
스토리지란 사전적인 의미로 창고, 혹은 저장소라는 의미를 갖고 있습니다. IT 분야에서도 스토리지라는 용어는 데이터를 저장하는 저장소를 뜻하는 용어로 사용합니다.
우선 객체스토리지를 알기위해서는 블록 스토리지(Block Storage), 파일 스토리지(File Storage), 객체 스토리지(Object Storage) 3가지를 알아야합니다.

블록 스토리지
- 파일의 형태로 데이터를 저장합니다.
- 블록 단위로 I/O를 진행합니다.
- 파일이 업데이트되면 변경된 부분의 블록만 업데이트합니다.
- 데이터베이스, 엔터프라이즈 소프트웨어 등에서 효율적인 I/O를 제공하는 스토리지 유형입니다.
블록스토리지는 정해진 블록안에 데이터를 저장합니다. 우리가 SQL에서 테이블을 만들때 각 칼럼별로 저장할 데이터를 설정해주고 이후의 데이터 삽입도 맨처음 설정한 값 범위안에서 저장해주는것과 유사합니다. 블록스토리지는 컴퓨터의 C드라이브, D드라이브와 유사합니다. 맨처음 파티션을 나누어주고 그 공간안에서 사용을 할 수 있습니다. 하지만 파일스토리지와 다른점은 파일스토리지는 1개의 경로만 갖는데 반하여 블록스토리지는 여러개의 경로를 가질 수 있습니다. C드라이브와 D드라이브를 네트워크를 통해서 공유하고 여러 사용자가 해당 드라이브를 참조하는것과 유사합니다. 물론 공유는 할 수 있지만 OS와의 연결은 한번에 1개만 가능합니다. 낮은 I/O 레이턴시를 보이기때문에 RDB와 같은 데이터베이스에 아주 적합합니다.
파일 스토리지
- 폴더와 파일로 이루어지는 계층구조를 갖는 스토리지입니다.
- 각 파일은 폴더에 종속되며 폴더 역시 다른 폴더에 종속될 수 있습니다.
케비넷을 떠올리면 이해하기 쉽습니다. 각각의 파일철들이 케비넷별로 저장되어있고 언제든 꺼내어 수정하거나 변경할 수 있습니다. 파일철을 찾으려면 어느 케비넷이 있는지 알고 있어야합니다. 마찬가지로 파일을 찾으려면 어느 경로에 있는지 알고있어야합니다. 파일철이 그리 많지 않다면 분류하고 정리하는데 큰 문제가없지만 파일철들이 계속해서 늘어나면 늘어날수록 점점 분류하고 정리하는 파일시스템에서의 인덱싱이 많아지고 찾기가 힘들어집니다.
객체 스토리지
- 객체 스토리지에서 각 객체는 데이터, 메타데이터, 키로 구성됩니다.
- 데이터는 이미지, 동영상, 텍스트 문서 또는 기타 유형의 파일입니다.
- 메타데이터에는 데이터의 내용, 사용 방법, 객체 크기 등에 대한 정보가 포함됩니다.
- 객체의 키는 고유한 식별자입니다.
- 어플리케이션 단에서 동작합니다. (블록 스토리지와 파일 스토리지는 모두 OS단에서 동작합니다.)
- 물리적 제약이 없기때문에 원하는 만큼 공간을 확장시킬 수 있습니다.
쉽게 말하면 S3나 Cloud Sotrage에서 폴더를 만들거나 다른 버킷으로 파일을 옮긴다고하여도 실제로 블록을 이동하거나 폴더에 종속되지 않고 사용자에게 그렇게 보이게 해주기만 해줍니다. (논리적인 스토리지입니다.)
아직 이해가 안되셨으면...
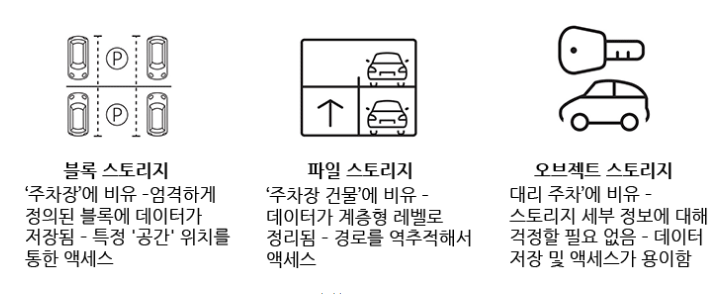
블록 스토리지는 주차장과 같습니다. 주차장이 꽉차면 더이상 주차할 수 없습니다. 그렇다면 필요한만큼 주차장을 늘려놓아야합니다. 파일 스토리지는 주차타워와 같습니다. 문제는 내 차를 타기 위해서는 주차타워가 한번 돌아가야합니다. 즉 주차가 많아지면 많아질수록 폴더가 깊어지고 많아질수록 차를 찾기가 힘듭니다. 오브젝트 스토리지는 발렛 파킹을 알아서 해줍니다. 강남이나 판교에서 발렛 맡겨보시면 아시겠지만 발렛 파킹 아저씨들은 정말 공간의 예술을 보여줍니다. 어떠한 공간도 정말 효율적이고 예술적으로 사용하고 공간의 낭비가 하나도 없도록 주차를 해줍니다.
Elastic Block Storage (EBS)
- Amazon EC2 인스턴스에서 사용할 수 있는 블록 수준 스토리지 볼륨을 제공하는 서비스입니다.
- 애플리케이션의 기본 스토리지로 쓰거나 시스템 드라이브용으로 쓰기 적합합니다.
- 인스턴스 생성 시 루트 디바이스 볼륨이 생성되며 사용 중에는 언마운트 할 수 없습니다.
- 인스턴스는 여러 볼륨을 마운트 할 수 있고, 추가 볼륨에 대해서는 사용 중이라도 마운트/언마운트가 가능합니다.
- 볼륨은 여러 인스턴스에 마운트 할 수 있습니다.
- EBS는 동일한 AZ 내에서 다른 인스턴스에 연결 가능합니다.
- 인스턴스 스토어 볼륨과느 ㄴ달리 EBS 기반 인스턴스는 중지/재시작이 가능합니다.
- 사용중인 EBS 이더라도 볼륨 유형과 사이즈를 변경할 수 있습니다. 사이즈 축소는 불가합니다.
EBS 볼륨 유형
Amazon EBS는 다음의 볼륨 유형을 제공하고 이러한 볼륨 유형은 성능 특성과 가격이 다르므로 애플리케이션의 필요에 맞게 스토리지 성능과 비용을 조정합니다.
- SSD (Solid-State Drive) : 주요 성능 특성이 IOPS인 작은 I/O 크기의 읽기/쓰기 작업이 자주 처리하는 트랜잭션 워크로드에 최적화 되어 있습니다.
- HHD(Hard Disk Drive) : 주요 성능 특성이 처리량인 대규모 스트리밍 워크로드에 최적화 되어 있습니다.
인스턴스 구성, I/O 특성 및 워크로드 요구량 등 여러가지 요인이 EBS 볼륨의 성능에 영향을 미칠 수 있습니다.
EBS 볼륨에서 프로비저닝된 IOPS를 완전히 사용하려면 EBS 최적화 인스턴스를 사용합니다.
Amazon EBS Snapshot
- 스냅샷을 이용하여 EBS 볼륨의 데이터를 S3에 자장할 수 있습니다.
- 증분식 백업이기 때문에 스냅샷은 하나이며, 마지막 스냅샷 이후 변경된 블록만 추가적으로 저장됩니다.
- 각 스냅샷에는 스냅샷을 만든 시점의 데이터를 새 EBS 볼륨에 복원하는데 필요한 정보가 들어 있습니다.
- EBS의 스냅샷은 S3에 저장되며 S3에 저장된 스냅샷으로 EBS 볼륨 복구 가능합니다.
- 암호화된 볼륨의 스냅샷은 자동으로 암호화 됩니다.
- 암호화된 스냅샷에서 생성되는 볼륨은 자동으로 암호화 됩니다.
- 암호화되지 않은 EBS에서 암호화된 스냅샷은 생성할 수 없습니다.
EBS 암호화
- EBS를 암호화함으로써 부팅 및 데이터 볼륨을 모두 암호화할 수 있습니다.
- 다음 유형의 데이터가 암호화 됩니다.
- 볼륨 내부 데이터
- 볼륨과 인스턴스 사이에서 이동하는 데이터
- 스냅샷에서 생성된 모든 볼륨 (스냅샷이 암호화되면 해당 스냅샷에서 생성된 볼륨은 자동 암호화)
- AES-256 알고리즘을 사용합니다.
Simple Storage Service (S3)
- 웹서비스 인터페이스 (HTTP)를 이용하여 웹에서 언제 어디서나 원하는 양의 데이터를 저장하고 검색할 수 있는 스토리지입니다.
- 버킷과 객체로 나뉘며, 저장하고자 하는 모든 요소는 하나의 객체로 저장되고, 오브젝트를 담는 곳이 바로 버킷입니다.
- S3 자체는 글로벌 서비스이지만 버킷을 생성할 떄에는 리전을 선택해야 합니다.
- 객체는 객체 데이터와 메타 데이터로 나뉘며, 각자의 고유한 URL을 가지며 해당 URL로 접속 가능합니다.
Amazon S3 적합한 경우
- 한 번 쓰고 여러 번 읽어야 하는 경우
- 컨텐츠가 다양하고, 데이터 양이 지속적으로 증가하는 경우
- 사용자가 많고, 데이터 접근이 일시적으로 급증하는 경우
Amazon S3 적합하지 않은 경우
- 여러 번 쓰기 작업을 해야하는 데이터
- 블록 스토리지가 필요한 경우
버킷의 정의와 특징
- 객체를 담고 있는 구성요소입니다.
- 크기는 무제한이며, 리전을 지정하여 버킷을 생성해야 합니다.
- 버킷의 이름은 반드시 고유해야 하며 중복될 수 없습니다.
- 한 번 설정된 버킷의 이름은 다른 계정에서 사용할 수 없습니다.
객체의 정의와 특징
- S3에 업로드 되는 1개의 데이터를 객체라 합니다.
- 키, 버전 ID, 값, 메타데이터 등으로 구성됩니다.
- 객체 하나의 최소 크기는 1Byte ~ 5TB
- 스토리지 클래스, 암호화, 태그, 메타데이터, 객체 잠금 설정 가능합니다.
- 객체의 크기가 매우 클 경우 멀티 파트 업로드를 통해 신속하게 업로드 가능합니다.
S3 스토리지 클래스
범용 (S3 Standard)
성능에 민감한 사용 사례(밀리초 액세스 시간을 필요로 하는 사례)와 자주 액세스되는 데이터를 위해 Amazon S3는 다음과 같은 스토리지 클래스를 제공합니다.
- S3 Standard : 기본 스토리지 클래스입니다. 객체를 업로드할 때 스토리지 클래스를 지정하지 않으면 Amazon S3가 S3 Standard 스토리지 클래스를 할당합니다.
- Reduced Redundancy : RRS(Reduced Redundancy Storage) 스토리지 클래스는 S3 Standard 스토리지 클래스보다 더 적은 중복성으로 저장될 수 있으며 중요하지 않고 재현 가능한 데이터용으로 설계되었습니다.
알수없거나 변화하는 액세스 (S3 Intelligent-Tiering)
S3 Intelligent-Tiering 스토리지 클래스는 성능 영향 또는 운영 오버헤드 없이 가장 비용 효율적인 스토리지 액세스 계층으로 데이터를 자동으로 이동하여 스토리지 비용을 최적화하도록 설계되었습니다. S3 Intelligent-Tiering은 액세스 패턴이 변경될 때 자주 액세스하는 계층과 저렴한 비용의 자주 액세스하지 않는 계층 간에 세분화된 객체 수준의 데이터를 이동함으로써 자동 비용 절감 효과를 제공합니다. Intelligent-Tiering 스토리지 클래스는 액세스 패턴을 알 수 없거나 예측할 수 없어 수명이 긴 데이터에 대해 스토리지 비용을 자동으로 최적화하려는 경우 이상적입니다.
S3 Intelligent-Tiering 스토리지 클래스는 두 액세스 계층에 객체를 저장합니다. 한 계층은 자주 액세스하는 데이터에 최적화되어 있으며 비용이 저렴한 다른 계층은 자주 액세스하지 않는 데이터에 최적화되어 있습니다. Amazon S3는 객체당 소액의 월별 모니터링 및 자동화 요금으로 S3 Intelligent-Tiering 스토리지 클래스에서 객체의 액세스 패턴을 모니터링하고 연속 30일 동안 액세스하지 않은 객체를 자주 액세스하지 않는 액세스 계층으로 이동합니다.
S3 Intelligent-Tiering 스토리지 클래스를 사용할 때 검색 요금은 없습니다. 빈번하지 않은 액세스 계층의 객체에 액세스하면 이 객체는 자동으로 빈번한 액세스 계층으로 다시 이동합니다. 객체가 S3 Intelligent-Tiering 스토리지 클래스 내 액세스 계층 간에 이동될 때는 계층화 요금이 추가로 적용되지 않습니다.
빈번하지 않은 액세스 (S3 Standard_IA , S3 One Zone-IA)
S3 Standard_IA 및 S3 One Zone-IA 스토리지 클래스는 수명이 길고 자주 액세스하지 않는 데이터용으로 설계되었습니다. 여기서 IA는 자주 액세스하지 않음을 의미합니다. S3 Standard-IA 및 S3 One Zone-IA 객체는 밀리초 액세스에 사용 가능합니다.(S3 Standard 스토리지 클래스와 동일합니다.) Amazon S3는 이러한 객체에 대한 검색 요금을 부과하므로 이러한 객체는 자주 액세스되지 않는 데이터에 가장 적합합니다.
예를 들어, S3 Standard-IA 및 S3 One Zone-IA 스토리지 클래스를 선택할 수 있습니다.
- 백업을 저장하는 경우.
- 자주 액세스되지는 않지만 그래도 밀리초 액세스가 필요한 오래된 데이터의 경우. 예를 들어, 데이터를 업로드할 때 S3 Standard 스토리지 클래스를 선택하고 수명 주기 구성을 사용하여 Amazon S3에 객체를 S3 Standard-IA 또는 S3 One Zone-IA 클래스로 전환하도록 지시할 수 있습니다.
이들 스토리지 클래스는 다음과 같은 차이가 있습니다.
- S3 Standard-IA — Amazon S3가 객체 데이터를 지리적으로 분리된 여러 개의 가용 영역에 중복 저장합니다(S3 Standard 스토리지 클래스와 유사함). S3 Standard-IA 객체는 가용 영역의 손실에 대한 복원성이 있습니다. 이 스토리지 클래스는 S3 One Zone-IA 클래스보다 뛰어난 가용성 및 복원성을 제공합니다.
- S3 One Zone-IA — Amazon S3가 객체 데이터를 한 개의 가용 영역에만 저장하므로 S3 Standard-IA보다 비용이 더 저렴합니다. 그러나 데이터는 지진 및 홍수와 같은 재해에 의한 가용 영역의 물리적 손실에 대해서는 복원성이 없습니다. S3 One Zone-IA 스토리지 클래스는 Standard-IA만큼 내구성이 있지만 가용성과 복원성은 더 낮습니다.
다음과 같이 하는 것이 좋습니다.
- S3 Standard-IA — 기본 데이터나 다시 생성할 수 없는 데이터의 복사본에만 사용합니다.
- S3 One Zone-IA — 가용 영역에 장애 발생 시 데이터를 다시 생성할 수 있는 경우, 그리고 S3 교차 리전 복제(CRR)를 설정하는 경우 객체 복제본에 사용합니다.
아카이브 (S3 Glacier 및 S3 Glacier Deep Archive)
S3 Glacier 및 S3 Glacier Deep Archive 스토리지 클래스는 저비용 데이터 아카이빙을 위해 설계되었습니다. 이러한 스토리지 클래스는 S3 Standard 스토리지 클래스와 동일한 내구성과 복원성을 제공합니다.
이들 스토리지 클래스는 다음과 같은 차이가 있습니다.
- S3 Glacier—분 단위로 데이터의 일부를 검색해야 하는 아카이브에 사용합니다. S3 Glacier 스토리지 클래스에 저장된 데이터는 최소 스토리지 기간이 90일이며 신속 검색을 사용하여 최소 1~5분 이내에 액세스할 수 있습니다. 90일 최소 기간 이전에 삭제했거나 덮어썼거나 다른 스토리지 클래스로 이전한 경우, 90일 요금이 부과됩니다.
- S3 Glacier Deep Archive—거의 액세스할 필요가 없는 데이터를 보관할 때 사용합니다. S3 Glacier Deep Archive 스토리지 클래스에 저장된 데이터의 최소 스토리지 기간은 180일이고 기본 검색 시간은 12시간입니다. 180일 최소 기간 이전에 삭제했거나 덮어썼거나 다른 스토리지 클래스로 이전한 경우, 180일 요금이 부과됩니다.
- S3 Glacier Deep Archive는 AWS에서 가장 저렴한 스토리지 옵션입니다. S3 Glacier Deep Archive에 대한 스토리지 비용은 S3 Glacier 스토리지 클래스를 사용하는 것보다 저렴합니다. 48시간 이내에 데이터를 반환하는 대량 검색을 사용하여 S3 Glacier Deep Archive 검색 비용을 절감할 수 있습니다.
멀티 파트 업로드
- 오브젝트의 크기가 클 경우, 이를 조각 내어 병렬적으로 처리하여 처리량을 개선하는 방법입니다.
- 보통 객체의 크기가 100MB 이상일 경우 사용하는 것을 권고하며 최대 가능 크기는 5TB입니다.
- 조각의 개수는 최대 1만개까지 가능하며, 조각의 크기는 대개 5MB ~ 5GB 정도입니다.
- GUI가 아닌 CLI를 통한 멀티 파트 업로드 API로 실행 가능합니다.
버전관리
- 동일한 객체에 대해 여러 버전을 가질 수 있도록 하는 기능입니다.
- 이미 S3에 존재하는 객체에 내용을 변경하여 업데이트할 경우 기존 버전이 사라지지 않고 이전 버전으로 존재할 수 있습니다.
- 최신 버전과 이전 버전 모두 확인 가능합니다.
- 기존 객체와 동일한 이름으로 파일을 업로드하면 덮어씁니다. (최신버전을 유지하지만 기존 버전이 삭제 됩니다.)
- 객체를 삭제하더라도 바로 삭제되는 것이 아닌 삭제 마커를 붙여 다시 복구할 수 있는 기능을 제공합니다.
수명주기 관리
- S3에 있는 오브젝트를 일정 시간 후에 다른 타입으로 변경하는 것을 의미합니다.
- 예를 들어, 자주 사용하던 Standard Type의 오브젝트를 60일 이후 더 이상 사용하지 않을 경우 Glacier Type으로 변환하여 비용을 줄일 수 있습니다.
- 현재 버전과 이전 버전에 대해 설정 가능합니다.
- 또한 완료되지 않은 멀티파트 업로드와 버전관리가 적용된 오브젝트의 삭제마커를 정리할 수 있습니다.
- 더 이상 사용하지 않은 오브젝트에 대해 만료기간을 설정하여 정한 기간 후 삭제하도록 설정 가능합니다.
- Standard-IA와 One Zone IA는 보관 후 30일 이후 이전 가능합니다.
정적 웹 사이트 호스팅
- S3로 하여금 정적 페이지를 제공할 수 있는 호스팅 기능을 제공하게 하는 것입니다.
- 활성화 후 특정 페이지를 지정하면 S3 접속 시 해당 페이지를 띄웁니다.
- 굳이 서버를 이용하지 않고 S3를 이용하여 웹 호스팅을 할 수 있습니다.
- 호스팅 뿐만 아니라 요청을 다른 버킷 혹은 도메인으로 리디렉션 가능합니다.
전송 속도 향상 (Transfer Acceleration)
- CloudFront의 Edge Location을 이용하여 파일 업로드를 보다 빠르게 하는 기능입니다.
- S3로 직접 업로드 하는 것이 아닌 가장 가까운 Edge Location으로 전송하고 아마존 백본 네트워크를 통해 S3로 도달합니다.
댓글과 공감 클릭은 더 좋은 글을 위한 응원이 됩니다.
관련글
AWS GUIDE #1
AWS 소개 요즘 클라우드 서비스가 IT 업계의 화두로 떠오르고 있습니다. 시장이 수백조원의 규모로 성장하고 있고, 아마존, 구글, MS 같은 거대 IT 기업들이 젖극적으로 시장을 개척하고 있습니다
papasjh.tistory.com
AWS GUIDE #2
글로벌 인프라 AWS 글로벌 클라우드 인프라는 업계에서 가장 안전하고 광범위하고 안정적인 클라우드 플랫폼으로 전 세계 데이터 센터를 통해 완전한 기능을 갖춘 200개 이상의 서비스를 제공합
papasjh.tistory.com
AWS GUIDE #3
Elastic Compute Cloud (EC2) 딥러닝은 경험적인 결과를 바탕으로 다양한 접근과 시도가 필요하나, 막대한 계산량이 요구됩니다. 이에 초성능 컴퓨팅(HPC)인프라 요구되고 인공지능 인프라 구축에 어려
papasjh.tistory.com
'Cloud > AWS SAA' 카테고리의 다른 글
| [한방정리] AWS SAA_C03 신규 추가 내용 정리 #1 (5) | 2022.08.09 |
|---|---|
| AWS GUIDE #5 (2) | 2022.07.22 |
| [한방정리] SAA_C02 VS SAA_C03 (3) | 2022.07.20 |
| AWS GUIDE #3 (0) | 2022.07.19 |
| AWS GUIDE #2 (0) | 2022.07.19 |






