솔루션 설계자는 데이터의 대규모 일괄 처리를 처리할 응용 프로그램을 개발하고 있습니다. Amazon S3는 입력 데이터를 저장하는 데 사용되고 다른S3버킷은 출력 데이터를 유지하는 데 사용됩니다.프로그램은 다른Amazon EC2인스턴스에 걸쳐 네트워크를 통해 데이터를 전송하여 데이터를 처리합니다.
솔루션 설계자는 데이터 전송의 총비용을 최소화하기 위해 무엇을 해야 합니까?
A.모든EC2인스턴스를Auto Scaling그룹에 배치합니다.
B.모든EC2인스턴스를 동일한AWS리전에 배치합니다.
C.모든EC2인스턴스를 동일한 가용 영역에 배치합니다.
D.여러 가용 영역의 프라이빗 서브넷에 모든EC2인스턴스를 배치합니다.
C
동일 가용 영역에서 Amazon EC2, Amazon RDS, Amazon Redshift, Amazon ElastiCache 인스턴스 및 Elastic Network Interface 간에 전송되는 데이터는 무료입니다.
B : 동일 AWS 리전 내 여러 가용 영역에 걸쳐 Amazon EC2, Amazon RDS, Amazon Redshift, Amazon DynamoDB Accelerator(DAX), Amazon ElastiCache 인스턴스, 탄력적 네트워크 인터페이스 또는 VPC 피어링 연결에서 ‘송신’ 및 ‘수신’되는 데이터는 각 방향에 대해 GB 당 0.01 USD가 부과됩니다.
비즈니스에서 만들고 반환하는 패키지 애플리케이션은 사용자 요청에 대한 응답으로 일회용 텍스트 파일을 동적으로 생성하고 반환합니다.이 회사는 이미Amazon CloudFront를 사용하여 콘텐츠를 배포하고 있지만 데이터 전송 비용을 더욱 최소화하려고 합니다.회사는 프로그램의 소스 코드를 편집할 수 없습니다.
솔루션 설계자는 비용을 절감하기 위해 어떤 조치를 취해야 합니까?
A. Lambda@Edge를 사용 하여 사용자에게 전송되는 파일을 압축합니다.
B.응답 시간을 줄이려면Amazon S3 Transfer Acceleration을 활성화합니다.
C. CloudFront배포에서 캐싱을 활성화하여 엣지에서 생성된 파일을 저장합니다.
D. Amazon S3멀티 파트 업로드를 사용하여 파일을 사용자에게 반환하기 전에Amazon S3로 이동합니다.
A
문제의 핵심은 '일회용 텍스트 파일'입니다. 일회용 텍스트 파일은 파일이 한 번만 사용되므로 CloudFront에서 캐시를 통해 다시 사용할 수 없습니다. 때문에 캐시를 통해 비용을 줄이는 것이 아닌, Lambda@Edge를 사용해 파일을 압축하면 파일 크기가 줄어들기 때문에 전송되는 데이터양이 적어지고, 이에 따라 전송 비용도 줄어듭니다.
CloudFront의 전송 비용을 줄이려면 콘텐츠를 Edge에 캐시 해야 합니다. 또한 추가로 비용을 줄이려면 Edge에서 요청 처리를 활성화하면 됩니다. 이렇게 설정하면 Edge 위치에서 요청을 처리하기 때문에, 기본 서버로 요청이 들어가는 횟수가 줄어듭니다.
No3.
비즈니스에는 소프트웨어 엔지니어링 목적으로AWS계정이 있습니다. AWS Direct Connect연결 쌍을 통해AWS계정은 회사의 온프레미스 데이터 센터에 액세스할 수 있습니다.가상 사설 클라우드에서 시작되지 않은 모든 트래픽은 가상 사설 게이트웨이를 통해 라우팅 됩니다.
개발 팀은 최근에 콘솔을 사용하여AWS Lambda함수를 구성했습니다.개발 팀은 회사 데이터 센터 내부의 사설 서브넷에 있는 데이터베이스에 대한 기능에 대한 액세스를 제공해야 합니다.
어떤 솔루션이 이러한 기준을 충족할까요?
A.적절한 보안 그룹이 있는VPC에서 실행되도록Lambda함수를 구성합니다.
B. AWS에서 데이터 센터로VPN연결을 설정합니다. VPN을 통해Lambda함수의 트래픽을 라우팅합니다.
C. Lambda함수가Direct Connect(DX)를 통해 온프레미스 데이터 센터에 액세스할 수 있도록VPC의 라우팅 테이블을 업데이트합니다.
D.탄력적IP주소를 생성합니다.탄력적 네트워크 인터페이스 없이 탄력적IP주소를 통해 트래픽을 보내도록Lambda함수를 구성합니다.
C
문제를 정리하자면 'AWS 서비스는 DX를 통해 기업의 온프레미스에 연결되는데, Lambda 함수를 새로 구성했기에 이 Lambda를 기업 온프레미스의 DB에 액세스하고 싶다'입니다. 이에 대해 설명하자면, VPN 또는 DX를 사용해 온프레미스 데이터베이스가 액세스할 수 있는 VPC에서 Lambda 함수를 실행하는 경우 이 통신은 공용 인터넷을 거치지 않고 VPN/DX를 통해 내부 네트워크에 있는 온프레미스 DB의 IP 주소로 직접 연결됩니다. 이때 이를 가능하게 하기 위해서는 VPN 혹은 DX를 사용한 후에는 온프레미스 서버에 연결이 가능하도록 라우팅 테이블을 반드시 '업데이트' 해야 합니다.
No4.
현재 온프레미스에서 웹 사이트를 유지 관리하는 비즈니스에서AWS클라우드로 이전하려고 합니다.웹 사이트는 단일 호스트 이름을 인터넷에 노출하지만 해당 기능을URL경로에 따라 고유한 온프레미스 서버 그룹으로 라우팅합니다.서버 그룹은 지원하는 서비스의 요구 사항에 따라 개별적으로 조정됩니다.회사의 온프레미스 네트워크는AWS Direct Connect링크를 통해 연결됩니다.
경로 기반 라우팅을 사용하여 트래픽이 적절한 서버 집합으로 전송되도록 하려면 솔루션 설계자가 무엇을 해야 합니까?
A.모든 트래픽을 인터넷 게이트웨이로 라우팅합니다.트래픽을 해당 경로를 지원하는 서버 그룹으로 라우팅하도록 인터넷 게이트웨이에서 패턴 일치 규칙을 구성합니다.
B.각 서버 그룹에 대한 대상 그룹이 있는 네트워크 로드 밸런서(NLB)로 모든 트래픽을 라우팅합니다. NLB에서 패턴 일치 규칙을 사용하여 트래픽을 올바른 대상 그룹으로 라우팅합니다.
C.모든 트래픽을ALB(Application Load Balancer)로 라우팅합니다. ALB에서 경로 기반 라우팅을 구성하여 해당 경로를 지원하는 서버의 올바른 대상 그룹으로 트래픽을 라우팅합니다.
D. Amazon Route 53을DNS서버로 사용합니다.해당 경로를 지원하는 서버 그룹에 대해 올바른Elastic Load Balancer로 트래픽을 라우팅하도록Route 53경로 기반 별칭 레코드를 구성합니다.
C
문제의 핵심은 '경로 기반 라우팅'입니다. ALB는 경로 기반 라우팅을 사용할 수 있습니다. 여기서 경로(Path)는 호스트가 제공하는 자원이 존재하는 위치를 뜻합니다. 사용자가 도메인 네임과 함께 경로를 입력하면 리스너(Listener)는 그 경로를 읽고 규칙(Role) 조건으로 삼을 수 있게 됩니다.
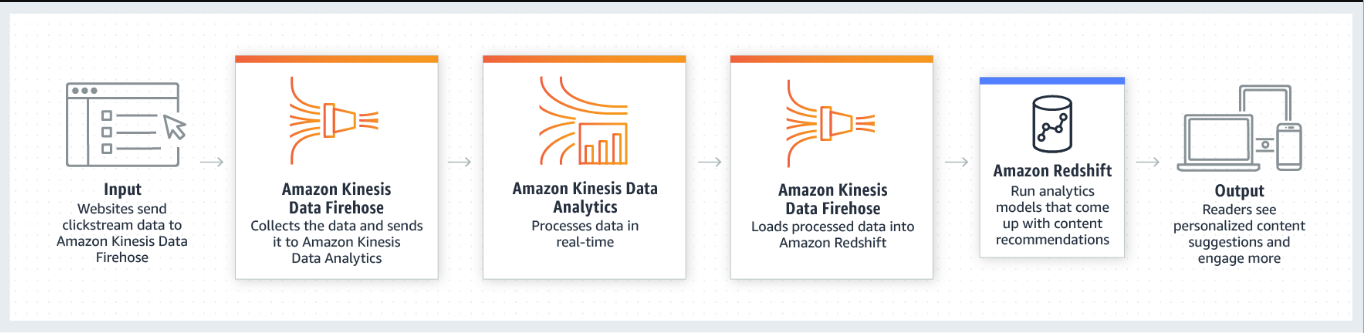
기업은 수많은 웹사이트에서 조직화된 클릭스트림 데이터를 수집하고 일괄 처리를 사용하여 분석합니다.회사는 매일 약1KB크기의 이벤트 레코드1억 개를 받습니다.매일 밤 조직은 비즈니스 분석가가 수집하는Amazon Redshift로 데이터를 가져옵니다.조직은 적시에 통찰력을 제공하기 위해 거의 실시간 데이터 처리로 전환하기를 원합니다.솔루션은 가능한 한 최소한의 운영 오버헤드로 스트리밍 데이터를 처리해야 합니다.
비용 효율성 측면에서 이러한 목표를 가장 잘 충족하는AWS서비스 조합은 무엇입니까? (2개를 선택하세요.)
A.아마존EC2
B. AWS배치
C. Amazon Simple Queue Service(Amazon SQS)
D. Amazon Kinesis Data Firehose
E. Amazon Kinesis데이터 분석
D,E
문제의 핵심은 '클릭스트림 데이터를 수집하며, 분석'입니다. 이 말은 실시간으로 데이터를 처리하고자 한다는 것이며, 기업에선 Redshift를 통해 데이터를 저장하고 있습니다. KDF와 KDA에 대한 시나리오를 설명하겠습니다. KDF를 통해 데이터를 실시간으로 수집하고, KDA로 데이터를 전송합니다. KDA로 전송된 데이터를 실시간으로 처리됩니다. 처리된 데이터는 다시 KDF를 통해 Redshift로 로딩됩니다.
Kinesis와 Redshift의 흐름도
문제풀이에 만족하신 분은 배너클릭, 좋아요 한번씩 하시고 AWS SAA 모의 시험 4th #2 함께 해요.